For context, this post is about Tensara, a competitive GPU programming platform. If you haven't heard of it before, the gist is to compete to write the fastest GPU kernel for a given mathematical workload (GEMM, Conv, Attention, etc). This post is also available on the Tensara blog.
A major part of making this platform work is building robust verification + benchmarking harnesses for our problems. This post is about the former: what it even means to “verify” floating-point GPU kernels, and our efforts to make our acceptance criteria more principled than "ehh rtol=1e-3 seems fine.”
Each Tensara problem is defined by a reference solution : a PyTorch implementation of the semantics of the problem. Let's represent the user submissions by . Given the appropriate inputs as defined by the problem, we compute a reference output: and a submission output: . We then decide whether to accept the submission by comparing and .
We use torch.allclose, which checks the elementwise inequality
where is atol (absolute tolerance) and is rtol (relative tolerance). The core problem is that we have to pick these bounds -- and if done by hand, they can feel arbitrary. This post is about choosing and in a way that's (1) justifiable and (2) stable.
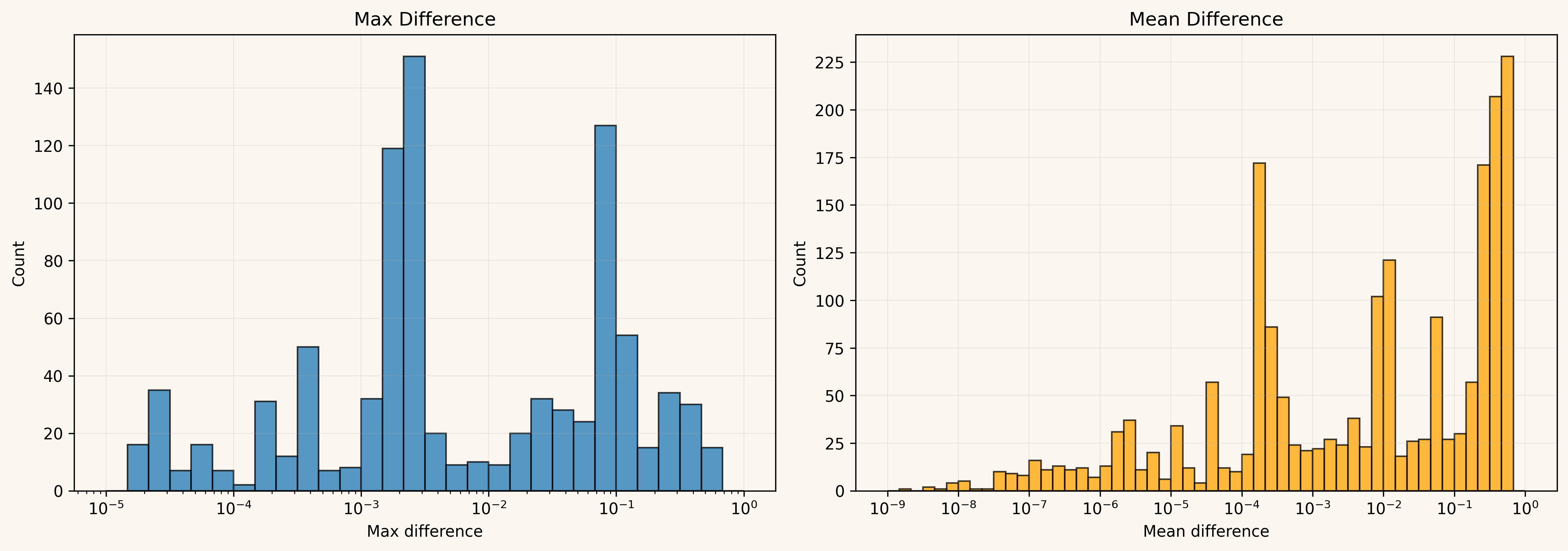
This is a distribution of the mean and max absolute differences across wrong submissions (filtered to those with mean/max difference < 1). Even among wrong submissions, the errors are often tiny: maximum differences frequently fall in the range , while mean differences reach down to , with many below .
Why should a submission that’s away be rejected? Why should it be accepted?
Rather than answer those case-by-case with hand-picked tolerances for every problem, we chose to make a general explicit policy decision of the "lower bound of correctness".
A submission should not be able to pass if it performs the entire computation in a strictly lower-precision regime than intended.
Concretely, if the intended correctness is float32 then a solution that simply runs the whole workload in float16 (or worse) should not pass the float32 correctness check. This fits in well with our plans to add lower precision regimes for problems (..soon?), as it lets us make the intended precision target explicit and enforce clear boundaries between solution sets across those modes.
The nice thing about having this explicit lower bound of correctness is that we can turn it into something quantitative. Let's say we have testcases with inputs for our problem. For each testcase , we first compute the reference output:
Next, we construct a corresponding “bad” output by forcing a fully lower-precision implementation in PyTorch after casting the inputs down. The details can vary based off the problem, but the intent is to make as a representative output that we do not want to accept as close enough to . This gives us a dataset of pairs:
that we want our eventual tolerances to reject.
Let's start with defining tensors and for each pair :
We can then write our torch.allclose() constraint as:
and both shape the same acceptance bound. matters most when is small, and matters most when is large, so choosing them independently is hard to reason about.
So we (heuristically) pick a typical scale . We then pin the ratio by enforcing . That collapses the problem to one free variable , with the absolute/relative tradeoff set by the problem’s numerics rather than by hand.
Plugging back into the constraint:
Let's define
Intuitively, is the per-element required for that entry to pass under the coupled rule .
All that’s left is choosing a single from the per-element requirements . Taking the max would make the tolerance hinge on one worst-case element, which can be fairly noisy across different problem types. So we soften it: we pick a percentile (we used 75%) and choose so that roughly three quarters of the entries still satisfy the bound (equivalently, one quarter of entries fail). Then we set .
Now we have one pair per testcase. We still need one global pair, and we don’t want it to be decided by a single outlier seed. So we score each testcase by , sort by , and take the median testcase.
That testcase’s becomes our global .
This still isn’t perfect, it’s a heuristic, but it’s much more grounded than what we had. There are a few obvious upgrades:
- Today we only anchor on bad pairs. If we can systematically generate near-boundary good pairs too, this turns into a clean separation problem (pick with margin).
- Input distributions matter. Keeping ranges small helps, but a better approach is probably multiple regimes (typical + stress) with explicit intent.
- Longer term we want explicit precision rungs (fp32, bf16/fp16, fp8, etc). Then verification is just making sure each tier doesn’t bleed into the next, and we can label what tier a submission effectively falls into.
- The median and percentile choices still have some arbitrariness. There’s room to analyze which kinds of workloads are sensitive to these knobs (and why), and which ones are basically indifferent to make a more informed choice.

For now, these changes put us in a better place to innovate in this context, with fewer ad hoc decisions along the way.
If you’re working on floating-point verification, benchmarks, or GPU-kernel weirdness and you made it this far, we’d probably get along. Reach out!